本文主要记录使用大模型开发的一些常见场景,作为一个初步开发指南:
- 如何本地部署大模型
- 如果基于API简单开发
- 简单的 RAG 应用
- MCP Server 应用 本地环境为 MacOS,开发语言使用 Python
本地部署大模型
首先需要安装本地大模型管理工具,建议使用 Ollama 即可
- 方式一:从官网下载并安装 Ollama
- 方式二:命令行直接安装
brew install ollama安装完成后,可以执行 ollama serve 命令启动 ollama ,随后通过以下命令拉取最新的 qwen3 8b 模型:
ollama pull qwen3:8b
Ollama 基本支持所有主流大模型,具体的模型列表,可以从 官网 查找(类比大模型的 dockerhub),不要使用过大参数的模型,本地开发视内存而定,建议 32b 以下,本地 7b 左右比较合适,后续更大参数的模型,一般通过平台提供的 API 使用。
- DeepseekR1-7b:
ollama pull deepseek-r1:7b - Qwen2-7b:
ollama pull qwen2:7b之后执行ollama run qwen3:8b即可运行大模型,直接提问即可。
其他的一些常用命令如下,其他像 create 创建大模型文件超出我们范围:
ollama list # 显示本地大模型
ollama ps # 显示运行的大模型
ollama rm xxx # 删除本地的大模型
 整体而言,本地部署还是非常简单的,有一点开发经验就可以快速上手。
整体而言,本地部署还是非常简单的,有一点开发经验就可以快速上手。
【可选】部署一个可视化界面,有多种选择,比如使用 Dify 这样的可视化流程编排工具,或者使用简单的 Open-WebUI 来本地对话。这里以部署 Open-WebUI 为例,通过 docker 运行:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果下载不了 ghcr 的镜像,考虑梯子,或者搜索国内镜像站比如 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/open-webui/open-webui:v0.6.5
拉取完成后,浏览器访问本机http://localhost:3000就可以配置并对话了

大模型开发
Ollama 提供的两个基础的 REST HTTP API,可以直接命令行 curl 可以看到结果:
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [
{
"role": "user",
"content": "why is the sky blue?"
}
]
}'
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:8b",
"prompt": "Why is the sky blue?"
}'
官网文档地址:https://github.com/ollama/ollama/blob/main/docs/api.md Python API 封装:https://github.com/ollama/ollama-python
本文后续的 python 都用新建的 venv
python3 -m virtualenv .env
source .evn/bin/activate
首先需要安装 ollama 相关的包 pip install ollama
简单使用如下:
# -*- coding: UTF-8 -*-
# !/usr/bin/env python3
import ollama
# 一次性返回所有内容
def simple(prompt):
content = ollama.generate(model="qwen3:8b", prompt=prompt)
print(content)
# 流的方式返回
def simple_stream(prompt):
chunks = ollama.generate(model="qwen3:8b", prompt=prompt, stream=True)
for chunk in chunks:
print(chunk.response, end='', flush=True)
# chat 接口
def simple_chat(prompt):
message = {"role": "user", "content": prompt}
content = ollama.chat(model="qwen3:8b", messages=[message])
print(content)
# 流式 chat 接口
def simpel_chat_stream(prompt):
message = {"role": "user", "content": prompt}
chunks = ollama.chat(model="qwen3:8b", messages=[message], stream=True)
for chunk in chunks:
print(chunk.message.content, end='', flush=True)
if __name__ == '__main__':
simpel_chat_stream("天空为什么是蓝色的?")
当然 Ollama 提供了 Client、AsyncClient,可以基于此开发:
import asyncio
from ollama import AsyncClient
client = AsyncClient(host="localhost:11434")
async def chat():
message = {'role': 'user', 'content': '天空为什么是绿色的'}
async for part in await client.chat(model="qwen3:8b", messages=[message], stream=True):
print(part.message.content, end='', flush=True)
asyncio.run(chat())
也可以要求大模型按照格式化方式输出,方便后续进一步处理(默认情况下的自然语言,比较难以格式化处理):
import ollama
from pydantic import BaseModel, Field
import json
class CountyInfo(BaseModel):
capital: str = Field(...)
population: float = Field(...)
area: float = Field(...)
resp = ollama.chat(
model="deepseek-r1:7b",
messages=[{
'role': 'user',
'content': '请介绍美国的首都、人口、占地面积,并以 JSON 格式返回。'
}],
format='json',
options={
'temperature': 0
}
)
content = resp.message.content
if not content:
raise ValueError('no response')
resp_json = json.loads(content)
print(resp_json)
struct_response = CountyInfo.model_validate(resp_json)
print(struct_response)
关于 pydantic 的使用,请参考官方文档 https://pydantic.com.cn/
当然这种方式在复杂场景下使用会遇到各种问题,以及不支持流程编排等,可以通过 langchain 来封装流程,使用 tool :
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
model = ChatOllama(model="deepseek-r1:7b")
template = """
你是一个乐于助人的AI,擅长于解决回答各种问题。
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model
# print(chain.invoke({"question": "你比GPT4厉害吗?"}))
messages=[('human',"天空为啥蓝色的")]
for chunk in model.stream(messages):
# print(chunk.content, end='', flush=True)
pass
def add(x,y):
return x+y
model.bind_tools([add])
model.generate()
更多关于 langchain 的内容,请参考官方文档:https://python.langchain.com/api_reference/
RAG
RAG 是在大模型的基础上,提供额外知识库(比如word,pdf 文件),提高回答的准确性。简单理解就是,对于文档新建向量数据库,以及相似度检索,把类似内容灌给大模型,基于这些内容回答,一种简单的 RAG 实现如下:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embeddings=local_embeddings)
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
len(docs)
from langchain_ollama import ChatOllama
model = ChatOllama(model="deepseek-r1:7b")
response_message = model.invoke("Simulate a rap battle between Stephen Colbert and John Oliver")
print(response_message.content)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
chain.invoke(docs)
这里文档索引使用的是 nomic-embed-text 模型。 RAG 比较难的是,PDF文件的文本化,对于复杂格式比如图表表格,目前还没有比较好的实现方案。
MCP
MCP 相当于把所有的 Tool 设计了一整套协议来发现调用,使得 tool 变得更通用,如下图:
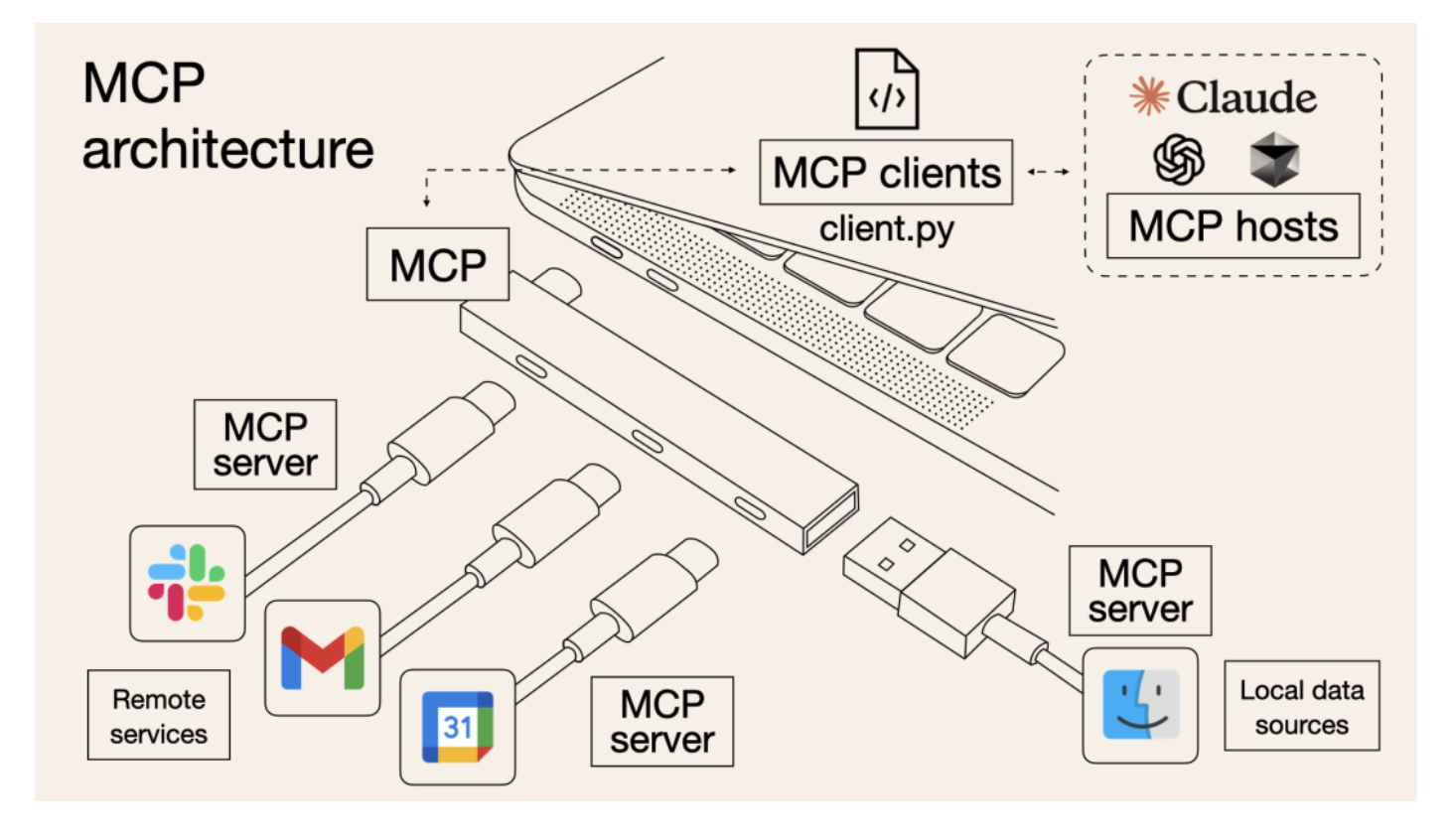
MCP 支持两种协议
- Stdio协议:一般需要依赖本地的一些工具,比如文件系统工具等
- SSE 协议:可以通过 HTTP 来暴露远程服务
通过安装 fastmcp,uv 等工具来开发 mcp server:
pip install fastmcp uv
一个简答的 MCP Server 服务如下:
from fastmcp import FastMCP
# 创建MCP服务器
mcp = FastMCP("TestServer")
# 我的工具:
@mcp.tool()
def magicoutput(obj1: str, obj2: str) -> int:
"""使用此函数获取魔法输出"""
print(f"输入参数:obj1:{obj1},obj2:{obj2}")
return f"输入参数:obj1:{obj1},obj2:{obj2},魔法输出:Hello MCP,MCP Hello"
if __name__ == "__main__":
mcp.run()
可以通过 fastmcp 来调试接口fastmcp dev server.py,注意需要先安装 nodejs (brew install nodejs)。

访问本机的 http://127.0.0.1:6274/#tools 就可以调试了
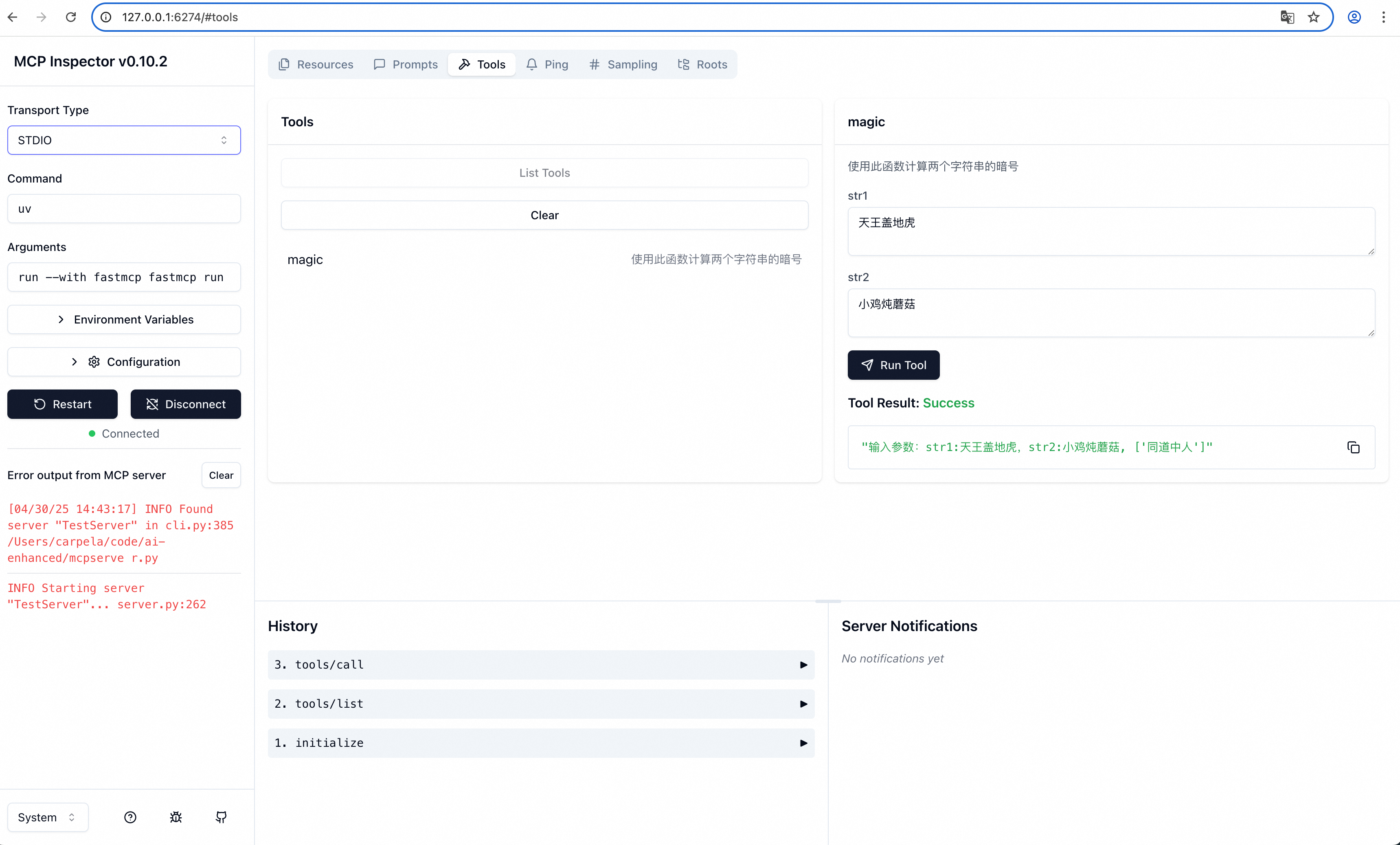
实际上,VSCode,以及各种 Studio 已经支持了 MCP,所以开发完的 mcp server 就可以直接跟各种 IDE 集成并使用了。
我们实际开发时,可以实现 MCP client 对接大模型,如下:
import asyncio
import threading
import queue
from pathlib import Path
from typing import Any, Optional, Union
from pydantic import BaseModel, Field, create_model
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from ollama import chat,Client
client = Client(
host='http://localhost:11434',
headers={'x-some-header': 'some-value'}
)
class OllamaMCP:
def __init__(self, server_params: StdioServerParameters):
self.server_params = server_params
self.request_queue = queue.Queue()
self.response_queue = queue.Queue()
self.initialized = threading.Event()
self.tools: list[Any] = []
self.thread = threading.Thread(target=self._run_background, daemon=True)
self.thread.start()
def _run_background(self):
asyncio.run(self._async_run())
async def _async_run(self):
try:
async with stdio_client(self.server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
self.session = session
tools_result = await session.list_tools()
self.tools = tools_result.tools
self.initialized.set()
while True:
try:
tool_name, arguments = self.request_queue.get(block=False)
except queue.Empty:
await asyncio.sleep(0.01)
continue
if tool_name is None:
break
try:
result = await session.call_tool(tool_name, arguments)
self.response_queue.put(result)
except Exception as e:
self.response_queue.put(f"错误: {str(e)}")
except Exception as e:
print("MCP会话初始化错误:", str(e))
self.initialized.set() # 即使初始化失败也解除等待线程的阻塞
self.response_queue.put(f"MCP初始化错误: {str(e)}")
def call_tool(self, tool_name: str, arguments: dict[str, Any]) -> Any:
"""
发布工具调用请求并等待结果
"""
if not self.initialized.wait(timeout=30):
raise TimeoutError("MCP会话未能及时初始化。")
self.request_queue.put((tool_name, arguments))
result = self.response_queue.get()
return result
def shutdown(self):
"""
干净地关闭持久会话
"""
self.request_queue.put((None, None))
self.thread.join()
print("持久MCP会话已关闭。")
@staticmethod
def convert_json_type_to_python_type(json_type: str):
"""简单地将JSON类型映射到Python(Pydantic)类型。"""
if json_type == "integer":
return (int, ...)
if json_type == "number":
return (float, ...)
if json_type == "string":
return (str, ...)
if json_type == "boolean":
return (bool, ...)
return (str, ...)
def create_response_model(self):
"""
基于获取的工具创建动态Pydantic响应模型
"""
dynamic_classes = {}
for tool in self.tools:
class_name = tool.name.capitalize()
properties: dict[str, Any] = {}
for prop_name, prop_info in tool.inputSchema.get("properties", {}).items():
json_type = prop_info.get("type", "string")
properties[prop_name] = self.convert_json_type_to_python_type(json_type)
model = create_model(
class_name,
__base__=BaseModel,
__doc__=tool.description,
**properties,
)
dynamic_classes[class_name] = model
if dynamic_classes:
all_tools_type = Union[tuple(dynamic_classes.values())]
Response = create_model(
"Response",
__base__=BaseModel,
__doc__="LLm响应类",
response=(str, Field(..., description= "向用户确认函数将被调用。")),
tool=(all_tools_type, Field(
...,
description="用于运行计算两个字符串暗号的工具"
)),
)
else:
Response = create_model(
"Response",
__base__=BaseModel,
__doc__="LLm响应类",
response=(str, ...),
tool=(Optional[Any], Field(None, description="如果不返回None则使用的工具")),
)
self.response_model = Response
async def ollama_chat(self, messages: list[dict[str, str]]) -> Any:
"""
使用动态响应模型向Ollama发送消息。
如果在响应中检测到工具,则使用持久会话调用它。
"""
conversation = [{"role":"assistant", "content": f"你必须使用工具。你可以使用以下函数:{[ tool.name for tool in self.tools]}"}]
conversation.extend(messages)
if self.response_model is None:
raise ValueError("响应模型尚未创建。请先调用create_response_model()。")
# 获取聊天消息格式的JSON模式
format_schema = self.response_model.model_json_schema()
# 调用Ollama(假定是同步的)并解析响应
response = client.chat(
model="qwen3:8b",
messages=conversation,
format=format_schema
)
print("Ollama响应", response.message.content)
response_obj = self.response_model.model_validate_json(response.message.content)
maybe_tool = response_obj.tool
if maybe_tool:
function_name = maybe_tool.__class__.__name__.lower()
func_args = maybe_tool.model_dump()
# 使用asyncio.to_thread在线程中调用同步的call_tool方法
output = await asyncio.to_thread(self.call_tool, function_name, func_args)
return output
else:
print("响应中未检测到工具。返回纯文本响应。")
return response_obj.response
async def main():
server_parameters = StdioServerParameters(
command="uv",
args=["run", "python", "mcpserver.py"],
cwd=str(Path.cwd())
)
# 创建持久会话
persistent_session = OllamaMCP(server_parameters)
# 等待会话完全初始化
if persistent_session.initialized.wait(timeout=30):
print("准备调用工具。")
else:
print("错误: 初始化超时。")
# 从获取的工具创建动态响应模型
persistent_session.create_response_model()
# 准备给Ollama的消息
messages = [
{
"role": "system",
"content": (
"你是一个听话的助手,上下文中有一系列工具。"
"你不需要直接给出问题的答案,只需要告诉调用工具的名字,"
"并按照实际情况设置好 tool 参数,"
)
},
{
"role": "user",
"content": "上一句:天王盖地虎,下一句:小鸡炖蘑菇。帮我判断这两个暗号能不能对的上"
}
]
# 调用Ollama并处理响应
result = await persistent_session.ollama_chat(messages)
print("最终结果:", result)
# 完成后关闭持久会话
persistent_session.shutdown()
if __name__ == "__main__":
asyncio.run(main())

使用 SSE 协议修改
# -*- coding: UTF-8 -*-
# !/usr/bin/env python3
from fastmcp import FastMCP
from starlette.applications import Starlette
from mcp.server.sse import SseServerTransport
from starlette.requests import Request
from starlette.routing import Mount, Route
from mcp.server import Server
import uvicorn
mcp = FastMCP("TestServer")
# 我的工具:
@mcp.tool()
def magic(str1: str, str2: str) -> bool:
"""使用此函数计算两个字符串的暗号"""
print(f"输入参数:str1:{str1},str2:{str2}")
result = False
if len(str1) == len(str2):
result = True
return f"输入参数:str1:{str1},str2:{str2}, 对暗号的结果:{result}"
## sse传输
def create_starlette_app(mcp_server: Server, *, debug: bool = False) -> Starlette:
"""Create a Starlette application that can serve the provided mcp server with SSE."""
sse = SseServerTransport("/messages/")
async def handle_sse(request: Request) -> None:
async with sse.connect_sse(
request.scope,
request.receive,
request._send, # noqa: SLF001
) as (read_stream, write_stream):
await mcp_server.run(
read_stream,
write_stream,
mcp_server.create_initialization_options(),
)
return Starlette(
debug=debug,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
if __name__ == "__main__":
mcp_server = mcp._mcp_server
starlette_app = create_starlette_app(mcp_server, debug=True)
uvicorn.run(starlette_app, host="127.0.0.1", port=11333)
运行调试和SSE server
fastmcp dev mcp_sse_server.py
uv run mcp_sse_server.py
MCP SSE Client 实现
import asyncio
import threading
import queue
from pathlib import Path
from typing import Any, Optional, Union
from pydantic import BaseModel, Field, create_model
from mcp import ClientSession, StdioServerParameters
from mcp.client.sse import sse_client
from ollama import chat,Client
client = Client(
host='http://localhost:11434',
headers={'x-some-header': 'some-value'}
)
class OllamaMCP:
def __init__(self, server_url):
self.server_url = server_url
self.request_queue = queue.Queue()
self.response_queue = queue.Queue()
self.initialized = threading.Event()
self.tools: list[Any] = []
self.thread = threading.Thread(target=self._run_background, daemon=True)
self.thread.start()
def _run_background(self):
asyncio.run(self._async_run())
async def connect_to_sse_server(self, server_url: str):
"""Connect to an MCP server running with SSE transport"""
# Store the context managers so they stay alive
self._streams_context = sse_client(url=server_url)
streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams)
self.session: ClientSession = await self._session_context.__aenter__()
# Initialize
await self.session.initialize()
# List available tools to verify connection
print("Initialized SSE client...")
print("Listing tools...")
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def _async_run(self):
await self.connect_to_sse_server(self.server_url)
try:
tools_result = await self.session.list_tools()
self.tools = tools_result.tools
self.initialized.set()
while True:
try:
tool_name, arguments = self.request_queue.get(block=False)
except queue.Empty:
await asyncio.sleep(0.01)
continue
if tool_name is None:
break
try:
result = await self.session.call_tool(tool_name, arguments)
self.response_queue.put(result)
except Exception as e:
self.response_queue.put(f"错误: {str(e)}")
except Exception as e:
print("MCP会话初始化错误:", str(e))
self.initialized.set() # 即使初始化失败也解除等待线程的阻塞
self.response_queue.put(f"MCP初始化错误: {str(e)}")
def call_tool(self, tool_name: str, arguments: dict[str, Any]) -> Any:
"""
发布工具调用请求并等待结果
"""
if not self.initialized.wait(timeout=30):
raise TimeoutError("MCP会话未能及时初始化。")
self.request_queue.put((tool_name, arguments))
result = self.response_queue.get()
return result
@staticmethod
def convert_json_type_to_python_type(json_type: str):
"""简单地将JSON类型映射到Python(Pydantic)类型。"""
if json_type == "integer":
return (int, ...)
if json_type == "number":
return (float, ...)
if json_type == "string":
return (str, ...)
if json_type == "boolean":
return (bool, ...)
return (str, ...)
def create_response_model(self):
"""
基于获取的工具创建动态Pydantic响应模型
"""
dynamic_classes = {}
for tool in self.tools:
class_name = tool.name.capitalize()
properties: dict[str, Any] = {}
for prop_name, prop_info in tool.inputSchema.get("properties", {}).items():
json_type = prop_info.get("type", "string")
properties[prop_name] = self.convert_json_type_to_python_type(json_type)
model = create_model(
class_name,
__base__=BaseModel,
__doc__=tool.description,
**properties,
)
dynamic_classes[class_name] = model
if dynamic_classes:
all_tools_type = Union[tuple(dynamic_classes.values())]
Response = create_model(
"Response",
__base__=BaseModel,
__doc__="LLm响应类",
response=(str, Field(..., description= "向用户确认函数将被调用。")),
tool=(all_tools_type, Field(
...,
description="用于运行计算两个字符串暗号的工具"
)),
)
else:
Response = create_model(
"Response",
__base__=BaseModel,
__doc__="LLm响应类",
response=(str, ...),
tool=(Optional[Any], Field(None, description="如果不返回None则使用的工具")),
)
self.response_model = Response
async def ollama_chat(self, messages: list[dict[str, str]]) -> Any:
"""
使用动态响应模型向Ollama发送消息。
如果在响应中检测到工具,则使用持久会话调用它。
"""
conversation = [{"role":"assistant", "content": f"你必须使用工具。你可以使用以下函数:{[ tool.name for tool in self.tools]}"}]
conversation.extend(messages)
if self.response_model is None:
raise ValueError("响应模型尚未创建。请先调用create_response_model()。")
# 获取聊天消息格式的JSON模式
format_schema = self.response_model.model_json_schema()
# 调用Ollama(假定是同步的)并解析响应
response = client.chat(
model="qwen3:8b",
messages=conversation,
format=format_schema
)
print("Ollama响应", response.message.content)
response_obj = self.response_model.model_validate_json(response.message.content)
maybe_tool = response_obj.tool
if maybe_tool:
function_name = maybe_tool.__class__.__name__.lower()
func_args = maybe_tool.model_dump()
# 使用asyncio.to_thread在线程中调用同步的call_tool方法
output = await asyncio.to_thread(self.call_tool, function_name, func_args)
return output
else:
print("响应中未检测到工具。返回纯文本响应。")
return response_obj.response
async def main():
# 创建持久会话
persistent_session = OllamaMCP(server_url="http://localhost:11333/sse")
# 等待会话完全初始化
if persistent_session.initialized.wait(timeout=30):
print("准备调用工具。")
else:
print("错误: 初始化超时。")
# 从获取的工具创建动态响应模型
persistent_session.create_response_model()
# 准备给Ollama的消息
messages = [
{
"role": "system",
"content": (
"你是一个听话的助手,上下文中有一系列工具。"
"你不需要直接给出问题的答案,只需要告诉调用工具的名字,"
"并按照实际情况设置好 tool 参数,"
)
},
{
"role": "user",
"content": "上一句:天王盖地虎,下一句:小鸡炖蘑菇。帮我判断这两个暗号能不能对的上"
}
]
# 调用Ollama并处理响应
result = await persistent_session.ollama_chat(messages)
print("最终结果:", result)
# 完成后关闭持久会话
# persistent_session.shutdown()
if __name__ == "__main__":
asyncio.run(main())
总结
整体而言,基于大模型开发应用的大方向都有所涉及。线上实际使用时,基本不会使用本地模型,而是以调用各云平台提供的 API 为主。同时,Agent 或者流程编排工具比如 Dify 没有涉及。Agent 可以理解为一个完整的应用,国内还有 Coze 这些平台,总之,基本概念都包含在本文范围。迈出第一步,后面的路还很长。
一些好用的 MCP Server: